



Introduction
Guest-Articles/2022/Compute-Shaders/Introduction
GPU Computing
In this chapter, we will have a look on the compute shader and try to understand how it works and how we can create and run a compute shader.
While traditionally the graphics card (GPU) has been a rendering co-processor which is handling graphics, it got more and more common to use graphics cards for other (not necessarily graphics related) computational tasks (General Purpose Computing on Graphics Processing Units; short:

A stream processor uses a function/
As stated above the most important (mandatory) aspect of programs running on GPUs is that they must be parallelizable. Sharing of memory is not easily possible and very limited for
(Even though this operation can be enhanced by the GPU using a kernel that accumulates sub-stream data in parallel and reducing the amount of serial accumulations for bigger streams. The results of the sub-stream data has to be combined in the host program afterwards).
It is important to keep this mandatory parallelism in mind when writing GPU
To summarize, compute shaders work great for many small parallel batches. Check out: Mythbusters Demo GPU versus CPU
Compute Shader Stage
To make GPU computing easier accessible especially for graphics applications while sharing common memory mappings, the OpenGL standard introduced the

Compute shaders are
To pass data to the compute shader, the shader needs to fetch the data for example via
The following table shows the data any shader stage operates on. As shown below, the compute shaders works on an "abstract work item".
| Stage | Data Element |
|---|---|
| Vertex Shader | per vertex |
| Tessellation Control Shader | per vertex (in a patch) |
| Tessellation Evaluation Shader | per vertex (in a patch) |
| Geometry Shader | per primitive |
| Fragment Shader | per fragment |
| Compute Shader | per (abstract) "work item" |
Compute space
The user can use a concept called

During execution of the
The
The image below shows how every

An example:
Given the
While it is possible to communicate using
Create your first compute shader
Now that we have a broad overview about compute shaders let's put it into practice by creating a "Hello-World" program. The program should write (color) data to the pixels of an image/texture object in the compute shader. After finishing the compute shader execution it will display the texture on the screen using a second shader program which uses a vertex shader to draw a simple screen filling quad and a fragment shader.
Since compute shaders are introduced in OpenGL 4.3 we need to adjust the context version first:
glfwWindowHint (GLFW_CONTEXT_VERSION_MAJOR, 4);
glfwWindowHint (GLFW_CONTEXT_VERSION_MINOR, 3);
Compile the Compute Shader
To being able to compile a compute shader program we need to create a new shader class. We create a new ComputeShader class, that is almost identically to the normal Shader class, but as we want to use it in combination to the normal shader stage we have to give it a new unique class name.
class ComputeShader
{
public:
unsigned int ID;
ComputeShader(const char* computePath)
{
...
}
}
Note: we could as well add a second constructor in the Shader class, which only has one parameter where we would assume that this is a compute shader but in the sake of clarity, we split them in two different classes.Additionally it is not possible to bake compute shaders into an OpenGL program object alongside other shaders.
The code to create and compile the shader is as well almost identically to the one for other shaders. But as the compute shader is not bound to the rest of the render pipeline we attach the shader solely to the new program using the shader type GL_COMPUTE_SHADER after creating the program itself.
unsigned int compute;
// compute shader
compute = glCreateShader (GL_COMPUTE_SHADER);
glShaderSource (compute, 1, &cShaderCode, NULL);
glCompileShader (compute);
checkCompileErrors(compute, "COMPUTE");
// shader Program
ID = glCreateProgram ();
glAttachShader (ID, compute);
glLinkProgram (ID);
checkCompileErrors(ID, "PROGRAM");
Check out the chapter Getting Started - Shaders to get more information about the Shader class.
Create the Compute Shader
With the shader class updated, we can now write our compute shader. As always, we start by defining the version on top of the shader as well as defining the size of the local
This can be done using the special layout input declaration in the code below. By default, the local sizes are 1 so if you only want a 1D or 2D
#version 430 core
layout (local_size_x = 1, local_size_y = 1, local_size_z = 1) in;
Since we will execute our shader for every pixel of an image, we will keep our local size at 1 in every dimension (1 pixel per
There is a limitation of
There is as well a limitation on the
As we define and divide the tasks and the compute shader groups sizes ourselves, we have to keep these limitations in mind.
We will bind the a 2d image in our shader as the object to write our data onto. The internal format (here rgba32f) needs to be the same as the format of the texture in the host program.
layout(rgba32f, binding = 0) uniform image2D imgOutput;
We have to use image2d as this represents a single image from a texture. While sampler variables use the entire texture including mipmap levels and array layers, images only have a single image from a texture. Note while most texture sampling functions use normalized texture coordinates [0,1], for images we need the absolute integer
With this set up, we can now write our main function in the shader where we fill the imgOutput with color values. To determine on which pixel we are currently operating in our shader execution we can use the following GLSL Built-in variables shown in the table below:
| Type | Built-in name | |
|---|---|---|
| uvec3 | gl_NumWorkGroups | number of set by |
| uvec3 | gl_WorkGroupSize | size of the defined with layout |
| uvec3 | gl_WorkGroupID | index of the |
| uvec3 | gl_LocalInvocationID | index of the current work item in the |
| uvec3 | gl_GlobalInvocationID | global index of the current work item (gl_WorkGroupID * gl_WorkGroupSize + gl_LocalInvocationID) |
| uint | gl_LocalInvocationIndex | 1d index representation of gl_LocalInvocationID (gl_LocalInvocationID.z * gl_WorkGroupSize.x * gl_WorkGroupSize.y + gl_LocalInvocationID.y * gl_WorkGroupSize.x + gl_LocalInvocationID.x) |
Using the built-in variables from the table above we will create a simple color gradient (st-map) on our image.
void main() {
vec4 value = vec4(0.0, 0.0, 0.0, 1.0);
ivec2 texelCoord = ivec2(gl_GlobalInvocationID.xy);
value.x = float(texelCoord.x)/(gl_NumWorkGroups.x);
value.y = float(texelCoord.y)/(gl_NumWorkGroups.y);
imageStore(imgOutput, texelCoord, value);
}
We will setup the execution of the compute shader that every
We can then write our calculated pixel data to the image using the
Create the Image Objecte
In the host program, we can now create the actual image to write onto. We will create a 512x512 pixel texture.
// texture size
const unsigned int TEXTURE_WIDTH = 512, TEXTURE_HEIGHT = 512;
...
unsigned int texture;
glGenTextures (1, &texture);
glActiveTexture (GL_TEXTURE0);
glBindTexture (GL_TEXTURE_2D, texture);
glTexParameter i(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameter i(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexParameter i(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameter i(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexImage2D (GL_TEXTURE_2D, 0, GL_RGBA32F, TEXTURE_WIDTH, TEXTURE_HEIGHT, 0, GL_RGBA,
GL_FLOAT, NULL);
glBindImageTexture(0, texture, 0, GL_FALSE, 0, GL_READ, GL_RGBA32F);
To find a deeper explanation of the functions used to setup a texture check out the Getting Started - Textures chapter. Here the
Executing the Compute Shader
With everything set up we can now finally execute our compute shader. In the drawing loop we can use/bind our compute shader and execute it using the
// render loop
// -----------
computeShader.use();
glDispatchCompute((unsigned int)TEXTURE_WIDTH, (unsigned int)TEXTURE_HEIGHT, 1);
// make sure writing to image has finished before read
glMemoryBarrier(GL_SHADER_IMAGE_ACCESS_BARRIER_BIT);
We first bind our shader using the
Before accessing the image data after the compute shader execution we need to define a barrier to make sure the data writing is completly finished. The
Rendering the image
Lastly, we will render a rectangle and apply the texture in the fragment shader.
// render image to quad
glClear (GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
screenQuad.use();
screenQuad.setInt("tex", 0);
glActiveTexture (GL_TEXTURE0);
glBindTexture (GL_TEXTURE_2D, texture);
renderQuad();
We will bind our texture now as sampler2D and use the texture coordinates of the rectangle to sample it.
The vertex and fragment shader are very simple as seen below.
Vertex Shader
#version 430 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec2 aTexCoords;
out vec2 TexCoords;
void main()
{
TexCoords = aTexCoords;
gl_Position = vec4(aPos, 1.0);
}
Fragment Shader
#version 430 core
out vec4 FragColor;
in vec2 TexCoords;
uniform sampler2D tex;
void main()
{
vec3 texCol = texture(tex, TexCoords).rgb;
FragColor = vec4(texCol, 1.0);
}
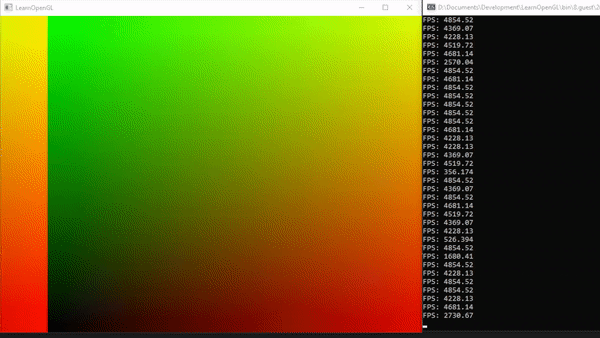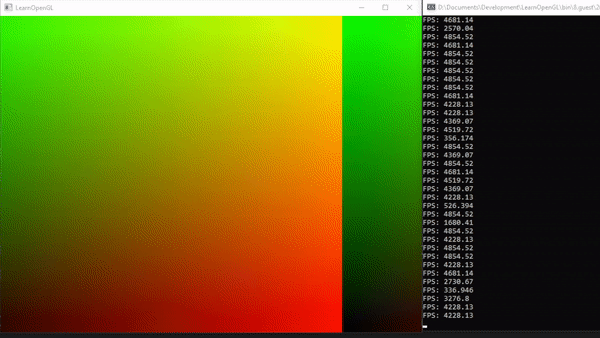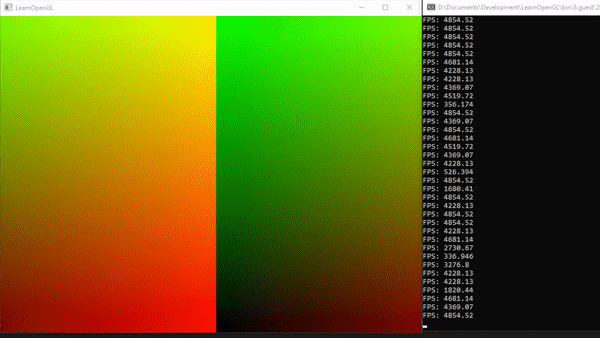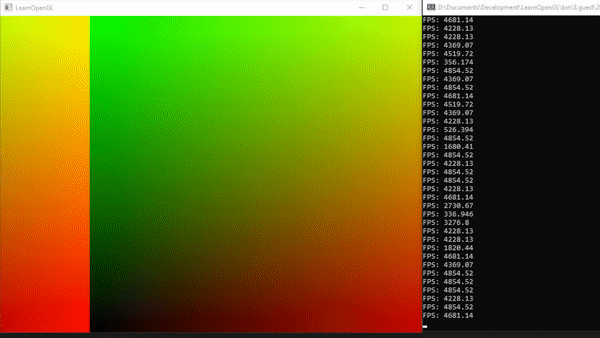
Image Output

Adding Time Variable and Speed Measuring
We will now add time to the program for performance measuring to test which settings (
// timing
float deltaTime = 0.0f; // time between current frame and last frame
float lastFrame = 0.0f; // time of last frame
int fCounter = 0;
// render loop
// -----------
...
// Set frame time
float currentFrame = glfwGetTime ();
deltaTime = currentFrame - lastFrame;
lastFrame = currentFrame;
if(fCounter > 500) {
std::cout << "FPS: " << 1 / deltaTime << std::endl;
fCounter = 0;
} else {
fCounter++;
}
The code above prints the frames per second limited to one print every 500 frames as too frequent printing slows the program down. When running our program with this "stopwatch" we will see that it will never get over 60 frames per second as glfw locks the refresh rate by default to 60fps.
To bypass this lock we can set the swap interval for the current OpenGL Context to 0 to get a bigger refresh rate than 60 fps. We can use the function
glfwMakeContextCurrent (window);
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
glfwSwapInterval(0);
Now we can get much more frames per seconds rendered/calculated. To be fair this example/hello world program is very easy and actually doesnt have any complex calculations so the calcuation times are very low.
We can now make our texture animated (moving from left to write) using the time variable. First, we change our computeShader to be animated:
#version 430 core
layout (local_size_x = 1, local_size_y = 1, local_size_z = 1) in;
// images
layout(rgba32f, binding = 0) uniform image2D imgOutput;
// variables
layout (location = 0) uniform float t; /** Time */
void main() {
vec4 value = vec4(0.0, 0.0, 0.0, 1.0);
ivec2 texelCoord = ivec2(gl_GlobalInvocationID.xy);
float speed = 100;
// the width of the texture
float width = 1000;
value.x = mod(float(texelCoord.x) + t * speed, width) / (gl_NumWorkGroups.x);
value.y = float(texelCoord.y)/(gl_NumWorkGroups.y);
imageStore(imgOutput, texelCoord, value);
}
We create a uniform variable t, which will hold the current time. To animate a repeating rolling of the texture from left to right we can use
the module operation
In the host program, we can assign the variable value the same way as we assign them for any other shader using
computeShader.use();
computeShader.setFloat("t", currentFrame);
Hence currentFrame is an altering value, we have to do the assignment in the render loop for every iteration.
The layout (location = 0) definition in front of the float variable is in general not necessary as the shader implementation queries the location of every variable on each uniform assignment. This might slow down the program execution speed if executed for multiple variables every render loop.
If you know that the location won't change and you want to increase the performance of the program as much as possible you can either query the location just once before the render loop and save it in the host program or hardcode it in the host program.
Altering local size
Lastly, we can make use of the
In this last section, we are going to add some local

For simplicity, we increase the resolution of our texture to get a number that can be divided by 10 without a rest. Here we will have 1,000,000 pixels though need 1 million shader
// texture size
const unsigned int TEXTURE_WIDTH = 1000, TEXTURE_HEIGHT = 1000;
We can now lower the amount of
glDispatchCompute((unsigned int)TEXTURE_WIDTH/10, (unsigned int)TEXTURE_HEIGHT/10, 1);
If we run the program without altering the shader we will see that only 1/100 of the image will be calculated.

To calculate the whole image again we have to adjust the local_size of the compute shader accordingly. Here we distribute the
#version 430 core
layout (local_size_x = 10, local_size_y = 10, local_size_z = 1) in;
layout(rgba32f, binding = 0) uniform image2D imgOutput;
layout (location = 0) uniform float t; /** Time */
void main() {
vec4 value = vec4(0.0, 0.0, 0.0, 1.0);
ivec2 texelCoord = ivec2(gl_GlobalInvocationID.xy);
float speed = 100;
// the width of the texture
float width = 1000;
value.x = mod(float(texelCoord.x) + t * speed, width) / (gl_NumWorkGroups.x * gl_WorkGroupSize.x);
value.y = float(texelCoord.y)/(gl_NumWorkGroups.y*gl_WorkGroupSize.y);
imageStore(imgOutput, texelCoord, value);
}
As seen above we have to adjust the ratio for the relative
You can find the full source code for this demo here.
Final Words
The above introduction is meant as a very simple overview of the compute shader and how to make it work. As it is not part of the render pipeline, it can get even more complicated to debug non-working shaders/programs. This implementation only shows one of the ways to manipulate data with the compute shader using
In upcoming following articles we will go into creating a particle simulation and deal with buffer objects to work on input data and output data after manipulation. As well as having a look on
Exercises
References
Contact: mail